Forget-free continual learning with winning subnetworks
ICML 2022 paper.
TLDR

Incrementally utilizing the network by binary masking the parameter,
masked parameters are not updated(freezed).
Prevent forgetting by freezing, use unused part of network as task grows.
Quick Look
- Authors & Affiliation: Haeyong Kang
- Link: https://proceedings.mlr.press/v162/kang22b/kang22b.pdf
- Comments: ICML 2022
- Relevance: 4.0
Research Topic
- Category (General): Continual Learning
- Category (Specific): Continual Learning, Lottery Ticket Theorem
Paper Summary (What)
- Problem statement
- Searching for optimal winning tickets during continual learning with iterative pruning methods requires repetitive pruning and retraining for each arriving task, which is impractical.
- Solutions
- Set a learnable parameter $S$ that corresponds with every elements in parameter $W$.
- Sort parameters by the value $S$, select top $c% percent,
- Use the selected parameters for the task.
- However, once a parameter has been used, do not update the parameter (freeze).
- Update zero-masked parameters and $S$.
- Compress binary mask $M$ with Huffman Coding.
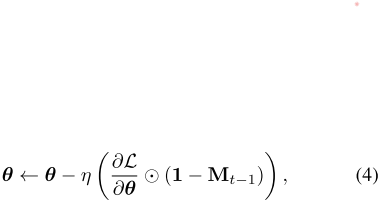
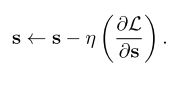
- Mask $M$ based on learnable ‘score’ S.
$M_{t-1} = \lor^{t-1}_{i=1} m_i$, which accumulates the binary mask.
i.e. Once $m_i = 1$ during $1 \leq i \leq t-1$, permenantly fixed as $1$.
- Incrementally using unused part of network.
First use $c \%$ amount of random parameters in the network,
keep mixing the sorted order by updating $S$,
try to use unused (those never had a high value $s$) parameters.
Notable References
Thoughts
Is there any guarantee that score $S$ really contributes to the saliency of according parameter?
$S$ being updated via SGD, thus even if $S$ really contributes after some iterations, it may not work as intended at the earlier phase.
Complex logic of selecting the lotter winner, but is it efficient/effective?
What is the difference between attatching new sub-network (i.e. LWF-like) and incrementally using the network, if the resulting network capacity is pretty much the same?
Footnote
아래와 같은 양식을 활용한다.
#
## Quick Look
- **Authors & Affiliation**: [Authors][Affiliations]
- **Link**: [Paper link]
- **Comments**: [e.g. Published at X / arXiv paper / in review.]
- **TLDR**: [One or at most two line summary]
- **Relevance**: [Score between 1 and 5, stating how relevant this paper is to your work. Usually filled in at the end.]
# Research Topic
- **Category** (General):
- **Category** (Specific):
# Paper Summary (What)
[Summary of the paper - a few sentences with bullet points. What did they do?]