DO DEEP NETWORKS TRANSFER INVARIANCES ACROSS CLASSES?
4학년 되면 편해지는거 아니었냐고… 살려줘…
Another Chelsea Finn’s paper incoming!
TLDR
If class sample size is below some threshold,
remove original \((x,y)\),
replace with \((T(x), y)\) when \(T(x)\) is a nuisance transformation.
Nuisance transform : location, scalem, aspect ratio, …
Quick Look
- Authors & Affiliation: Allan Zhou & Fahim Tajwar, Chelsea Finn
- Link: https://arxiv.org/abs/2203.09739
- Comments: ICLR2022
- Relevance: 4, quite notable
Research Topic
- Category (General): Transfer Learning
- Category (Specific): Transfer Learning, Continual Learning, Artificial Neural Network
Paper Summary (What)
- Q : How well do neural nets transfer class-agnostic invariances
learned from large (in terms of sample size) classes to small classes? - Claim : generative approach suggested (Generative Invariance Transfer) helps,
however invariance transfer is still poor, even applying balancing techniques. - Set of notations:
input as \((x,y)\), \(y \in {1, \cdots C}\), weight \(w\)
model \(\hat{P}_{w}(y = j | x)\), estimate label \(y\) given input \(x\)
\(T(\cdot | x)\) : nuisance transformation distribution.
nuisance transformation : location, scale, aspect ratio, … etc. - Definition of a “good” classifier?
invariant to \(T(\cdot | x)\),
i.e. \(\hat{P}_{w}(y = j | x) = \hat{P}_{w}(y = j | x^{trans})\)
when \(x^{trans} = T(x)\), transformed \(x\).
i.e. same label prediction for both original input \(x\), transformed \(T(x)\) -
Invariance metric : eKLD (estimated KL Divergence)
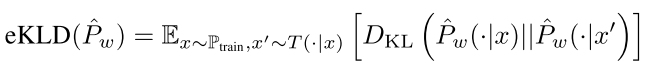
Equal with \(\sum_{x \in P_{train}} \hat{P}_{w}( \cdot | x) \log \frac{\hat{P}_{w}( \cdot | x)}{\hat{P}_{w}( \cdot | T(x))}\) - average KL Divergence, relative entrophy, statistcal distance
i.e. avg diff of encoding bits - \(T_{a-priori}\) unknown (당연! 알면 이걸 왜…)
따라서 rotation 같은 방법 사용, \(T = {T_{rotation}, T_{erosion}, \cdots}\) - \(T\) != data augmentation!
하나의 input \(x\) 에 대해서, multiple randomly chosen transform methods 가능.
e.g)rotate(erosion(x))등 가능. \(\rightarrow\) Contrastive learning과 직결? - Solution : Generative Invariance Transfer
Objective : transfer invariance across classes by explicitly learning underlying \(T\) - learn input-conditioned generative model \(T_{mock}(\cdot | x) \sim T(\cdot | x)\)
→ assume T_mock is same as orignial T - based on multimodal image-to-image translation
- Algorithm
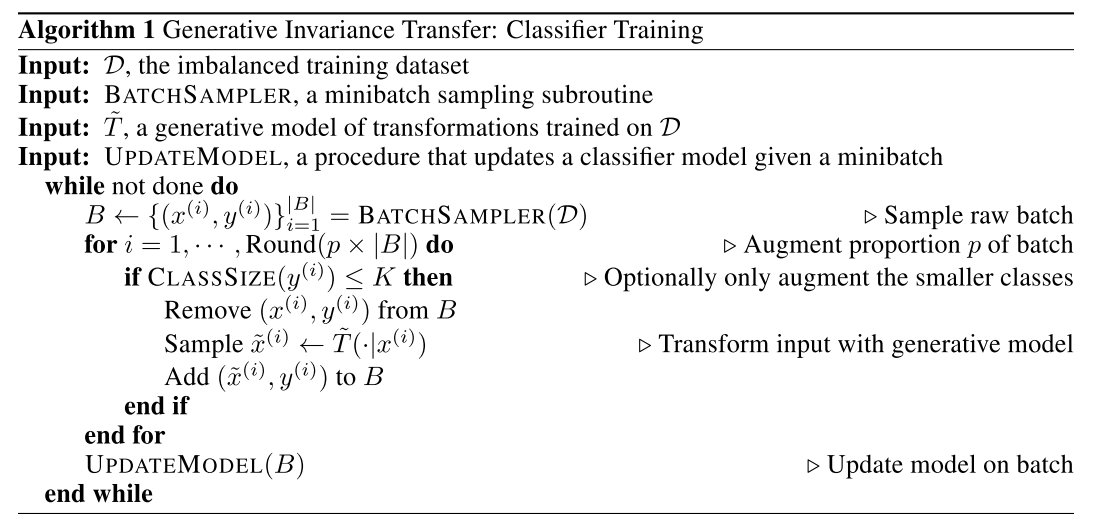
sample batch, either random or relative to sample sizes per class
if class_size(y_i) <= threshold
then:
remove original (x,y)
replace with (T(x), y) --> 'generative'
update model based on new batch
- remaining questions from authors:
why do deep neural nets struggle with class-agnostic invariance transfer in the first place?
Thinkings
물론 contrastive learning은 SSL 이지만, 그냥 똑같은거 아닌가?
\(T\) 의 (orthonormal) basis? 그냥 random selection이 맞나?
결과를 보면 \(10^3\) 넘어가면서 부터 GIT의 효능 역전됨.
\(\rightarrow\) class sample size 충분히 커지면 그냥 ‘잘’ 정제된 이미지를 많이 보는게 낫다.
Notable References
- Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. Multimodal unsupervised image-toimage translation. In Proceedings of the European conference on computer vision (ECCV), pp. 172–189, 2018.
- Alessandro Achille and Stefano Soatto. Emergence of invariance and disentanglement in deep representations. The Journal ofMachine Learning Research, 19(1):1947–1980, 2018.
- 위에거는 원래 CVPR2016의 저널버전. An Empirical Evaluation of Current Convolutional Architectures’ Ability to Manage Nuisance Location and Scale Variability. N. Karianakis, J. Dong and S. Soatto. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
Footnote
아래와 같은 양식을 활용한다.
#
## Quick Look
- **Authors & Affiliation**: [Authors][Affiliations]
- **Link**: [Paper link]
- **Comments**: [e.g. Published at X / arXiv paper / in review.]
- **TLDR**: [One or at most two line summary]
- **Relevance**: [Score between 1 and 5, stating how relevant this paper is to your work. Usually filled in at the end.]
# Research Topic
- **Category** (General):
- **Category** (Specific):
# Paper Summary (What)
[Summary of the paper - a few sentences with bullet points. What did they do?]